
The new normal that changes the way we do AI. Here is how, with illustrated examples
After two days of intense debate, the United Methodist Church has agreed to a historic split - one that is expected to end in the creation of a new denomination, one that will be "theologically and socially conservative," according to The Washington Post.
You might be wondering what this bizarre and trifling text has in common with AI, but in fact, it does. It is one of the news articles generated from the biggest ever and most sophisticated neural network, namely the GPT-3. If the text befuddles you, don’t worry, you’re not the only one. Only 12% of the pundits got it right. That’s not a typo. GPT-3 mastered many tasks that were considered human-only, setting the bar ever higher.
In the industry, there is a burgeoning need for intelligent systems working out-of-the-box with delicate specifications. Be it analyzing different text sources to predict the stock market tendency, detecting fake news, or simply answering questions like what color is Kardashian's hair (go for it, ask Google or Bing). We can use GPT-3 as a pre-trained model and make it learn any task we want: generating poems, code, spreadsheets, even some simple mobile and web applications.
Building and training such a pervasive and intelligent NLP system from scratch was never a problem. We only need a few million dollars to train the final version of it, without counting all the trials and errors throughout the process. The apocryphal sum for training GPT-3 is $4.6 million. Now, that is a problem. Not everyone can afford such commodities, especially the young start-ups aiming to build disruptive NLP-based applications.
Being such an elusive task, it doesn’t make sense to start from scratch and reluctantly fail over and over again. Instead, we need to adopt a new paradigm and take advantage of the pre-trained models, a strategy that is still not fully adopted in the industry.
In the pursuit of this idea, through illustrated examples, I’m going to show you what lies at the heart of what we as machine learning engineers want to achieve: how to build better AI applications.
Transformers: the abolishing of the recurrence
Generally in machine learning, there are two casts of practitioners: the first who admire convolutional neural networks (CNNs), and the others who admire recurrent neural networks (RNNs). Of course, there is an interplay between them in some scenarios.
Certainly, the RNNs are the hallmark of NLP, and for quite good reason. NLP is a sequencing task where words have a strict order and uncover cues for the next ones. Due to this temporal nature, the most obvious choice is to use RNNs. However, there are numerous impediments to their successful employment. First of all, the everlasting problem of vanishing and exploding gradients, being extremely slow, and on top of everything, they are not parallelizable.
Starting from the hypothesis that words that group together have a similar meaning, the word2vec word embeddings were coined. This was a major step toward adopting pre-trained models at scale in NLP, besides the ability to mathematically conclude that the words “cat” and “dog” are closely related.
This shift culminated with the invention of the fully convolutional Transformer architecture pre-trained in a self-supervised manner. The model is summarized in the figure below. The scope of this text is too short for an exhaustive drill of the Transformer, thus I refer readers to the excellent blog “The Annotated Transformer”.
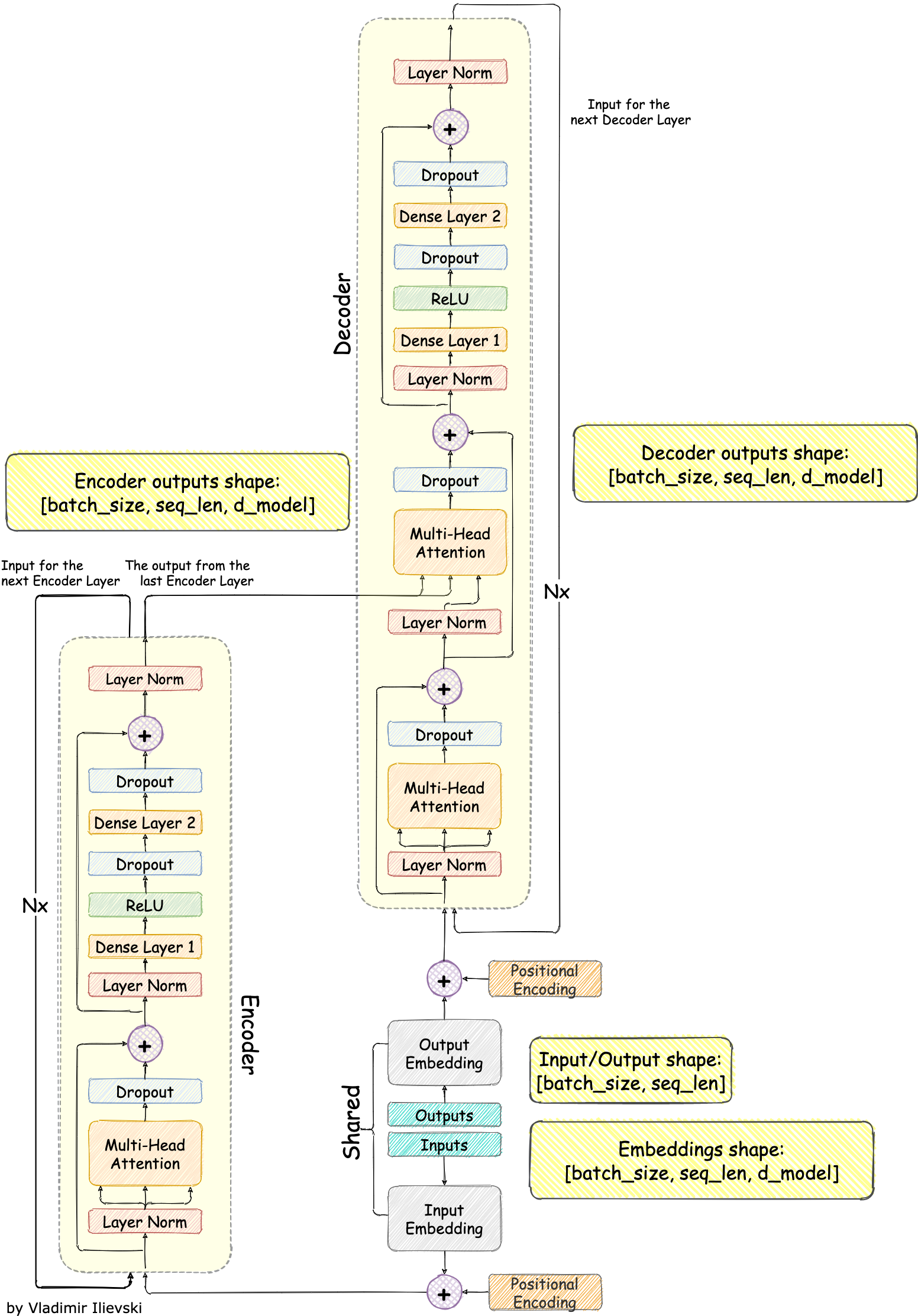
Fig. 1: Transformer Model
The main message here is: this superposition of the concepts propelled the paradigm shift of re-using pre-trained models and slowly abolishing the RNN use in NLP. As never before, with a decent amount of data and processing power it is now possible to craft a custom, top-notch NLP module.
This zoo of ready-to-use pre-trained Transformer models is becoming the “new normal”, creating an exquisite platform, an ecosystem in which many ideas can grow and blossom.
Let’s get to the nuts and bolts and see how to take advantage of this impetus and start creating better NLP apps.
Enter BERT
No, not the one from Sesame Street, but the Transformer-based model called “Bidirectional Encoder Representations from Transformers” or BERT in short.
The original paper was first introduced in 2018 along with the open-source implementation distributed with a few already pre-trained models. Along with the first version of GPT, it was one of the first models of this kind. After this, an entire concoction of pre-trained models accessible through a programming interface has spurred off.
Conceptually, the BERT model is quite simple, it is a stack of Transformer Encoders as depicted in the figure below:
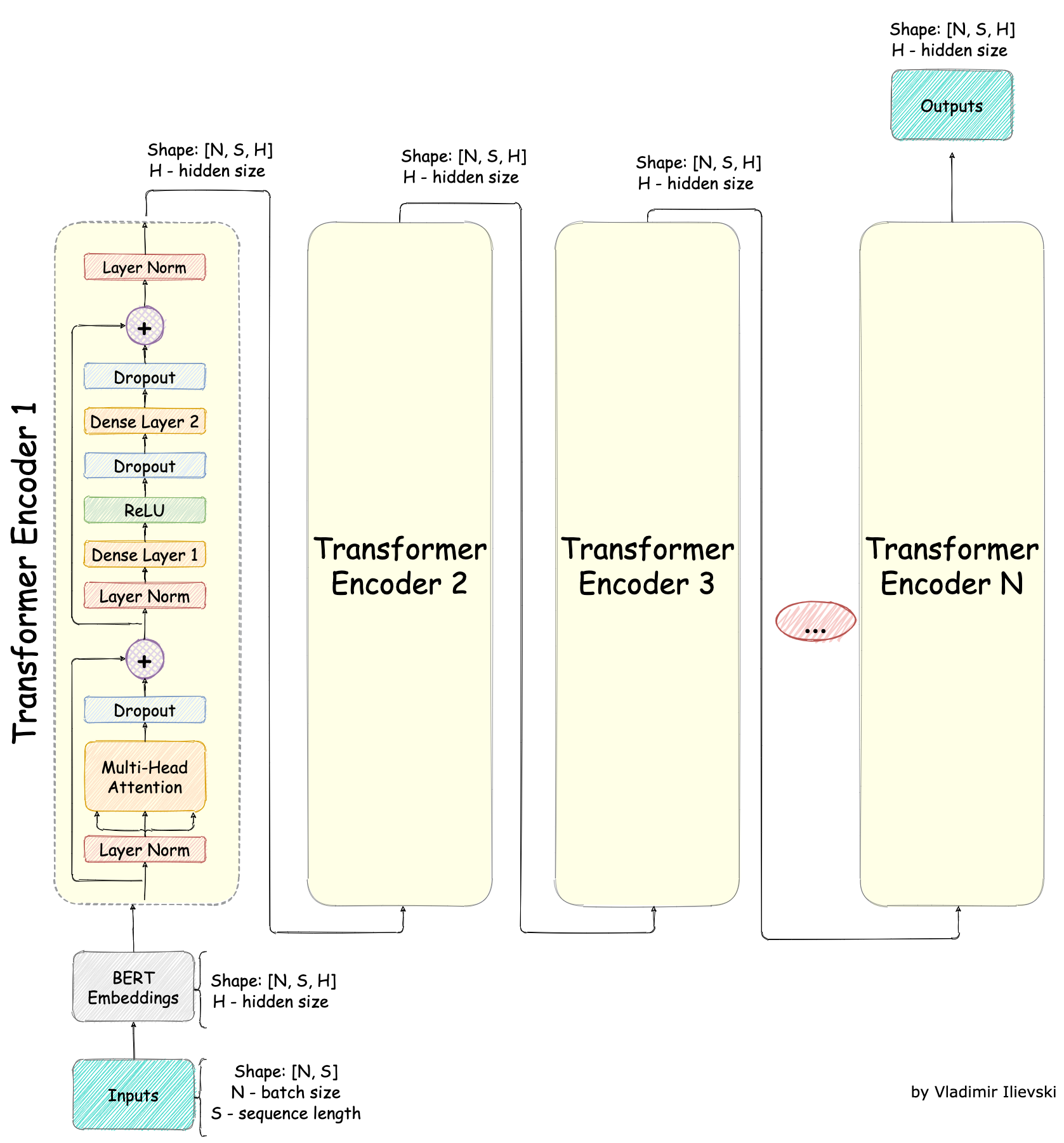
Fig. 2: BERT Model
This puppetware, as it is popularly referred to, was created with one goal in mind: to be a general task-agnostic pre-trained model that can be fine-tuned on many downstream tasks. To achieve this, the input/output structure and the pre-training procedure are designed to be complementary and flexible enough for a wide variety of downstream tasks. One thing is for sure, and that is:
“In order to use a pre-trained BERT model properly, the most important task is to understand the expected input and output.”
Input/Output
Both the input and output are on the level of individual tokens, such that for each token there is a corresponding multidimensional array of size H.
The input consists of two textual segments A and B separated by a special token designated as [SEP]. Additionally, there is always one special token at the beginning denoted as [CLS]. Having this input structure, the final input token representation is expressed as a sum of three embeddings: WordPiece embeddings, segment embeddings (token belongs to segment A or B), and positional embeddings (global position encoding of the token). There is a particular reason behind this mixture of three different embeddings, however, the most important thing to remember is that each token is now projected to a dimension of size H. This dimension persists through the entire BERT model. All of this is illustrated in the figure below:
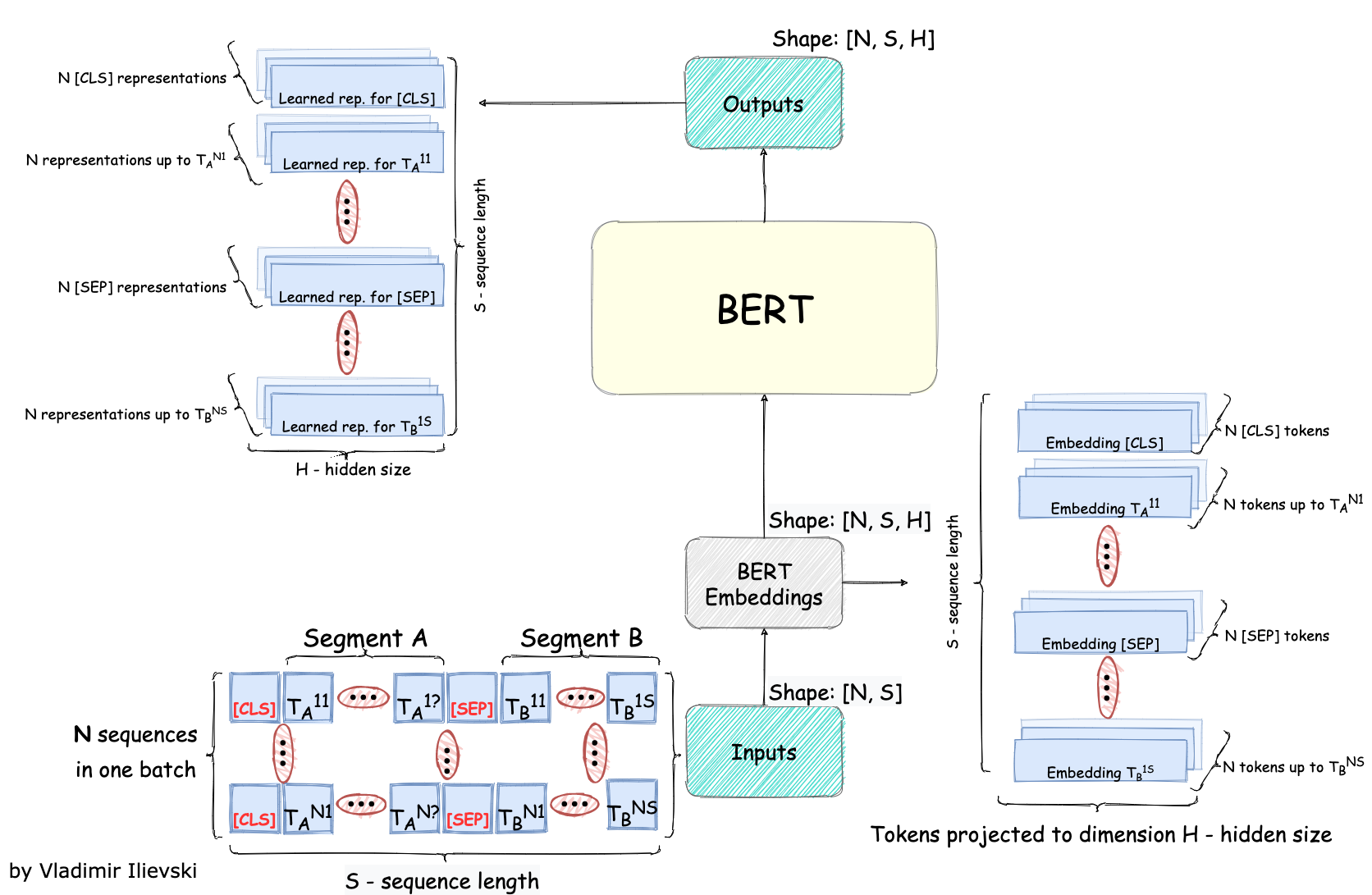
Fig. 3: BERT Input and Output
The output is a learned representation of size H for each input token. All of the outputs are left to be used furthermore by the engineers depending on the use case. First, the output representation for the special token [CLS] can be used for any text classification task. Second, the output representations of the actual word tokens can be used in any language understanding assignment.
Pre-training
The pre-training is based on two techniques: 1. Masked Language Modeling (MLM) and 2. Next Sentence Prediction (NSP).
The MLM task uses the same assumption as in word2vec: words that appear in the same context have a similar meaning. Thus, it selects 15% of the input words at random for possible masking. Then, 80% of them are masked, 10% are replaced with a random word and the last 10% are left unchanged. Finally, the BERT outputs for the randomly selected words are passed in a softmax output over the entire vocabulary.
The NSP task extends the scope of the MLP task by capturing dependencies between sentences. To accomplish this, 50% of the time segment B is the de facto next segment after A, and the remaining 50% of the time it is some random choice. Both tasks are shown in the figure below:
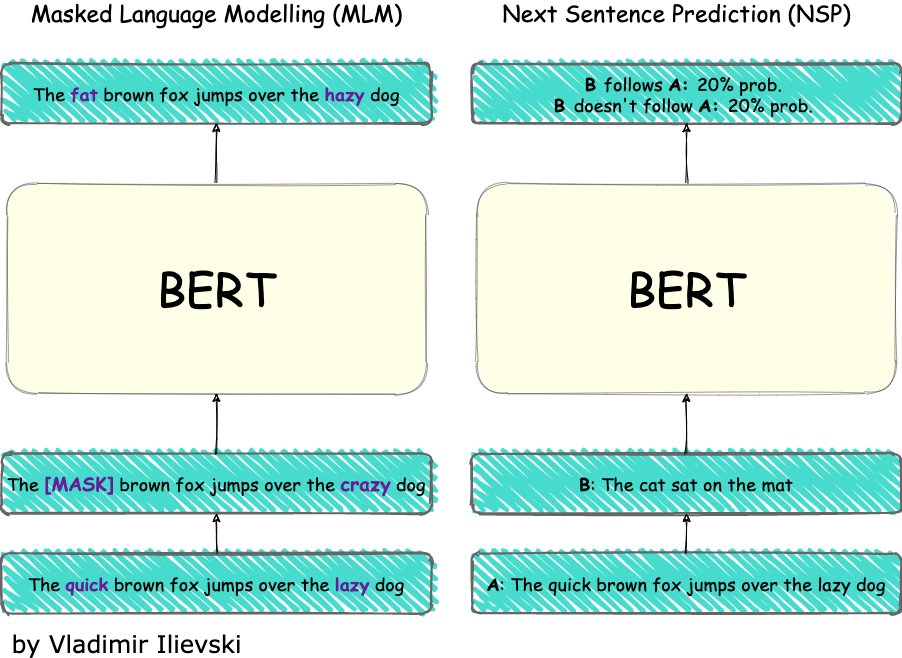
Fig. 4: BERT pre-training
In the original paper, there are 2 pre-trained models: 1. BERT-Base, containing 110 million parameters and 2. BERT-Large containing 340 million parameters. There is no wonder why this model knows almost everything. Both models are pre-trained using the Book Corpus dataset (800 million words) and the entire English Wikipedia (2500 million words).
Basic usage of BERT
As noted earlier there is a trove of open-source and pre-trained BERT models ready to be used by almost everyone. One such amazing repository is the one offered by Huggingface 🤗, and trust me, it is quite straightforward to take advantage of this mighty machinery. The code below demonstrates this:
1 2 3 4 5 6 7 8 9 10 11 |
from transformers import BertTokenizer, BertModel import torch tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') inputs = tokenizer("[CLS] This is very awesome!", return_tensors="pt") outputs = model(**inputs) # the learned representation for the [CLS] token cls = outputs.last_hidden_state[0, 0, :] |
Now, let’s see what kind of NLP applications we can develop with BERT.
BERT for Text Classification
Sentiment analysis epitomizes text classification, but its span is much wider. Text classification is a hodgepodge of many things. It ranges from classifying single sentences and reviews to categorizing entire documents.
The task of text classification is to take some text corpora and automatically assign a label to it. It might be handy in many different situations, as summarized in the following section.
Use Cases
Text classification can be used to automate the following tasks, but it is not limited to:
- Sentiment Analysis: detect subjectivity and polarity in a text. It is beneficial to understand our customers, whether they feel satisfied or not from our service.
- Intent classification: understand the topic of the user’s utterance. This can be helpful in our chatbot or to automatically route the request to the right agents to take care of.
- Document categorization: automatically entitle labels to textual documents. This can ameliorate the document retrieval in our product or organization, taking into consideration the rule of thumb that nearly 80% of corporate information exists in textual format.
- Language detection: as absurd as it sounds, but sometimes it is crucial to first detect the language in which a given sentence is written.
- Customer categorization: group social media users into cohorts. This is important for the marketing teams for the sake of segmenting the different casts of potential customers.
How to do it with BERT
If you need any kind of text classification, look no further. With the help of BERT or BERT-like models already at our disposal, we can craft reliable and functional text classification systems. In the figure below, it is demonstrated how we can easily adapt a pre-trained BERT model for any text classification task:
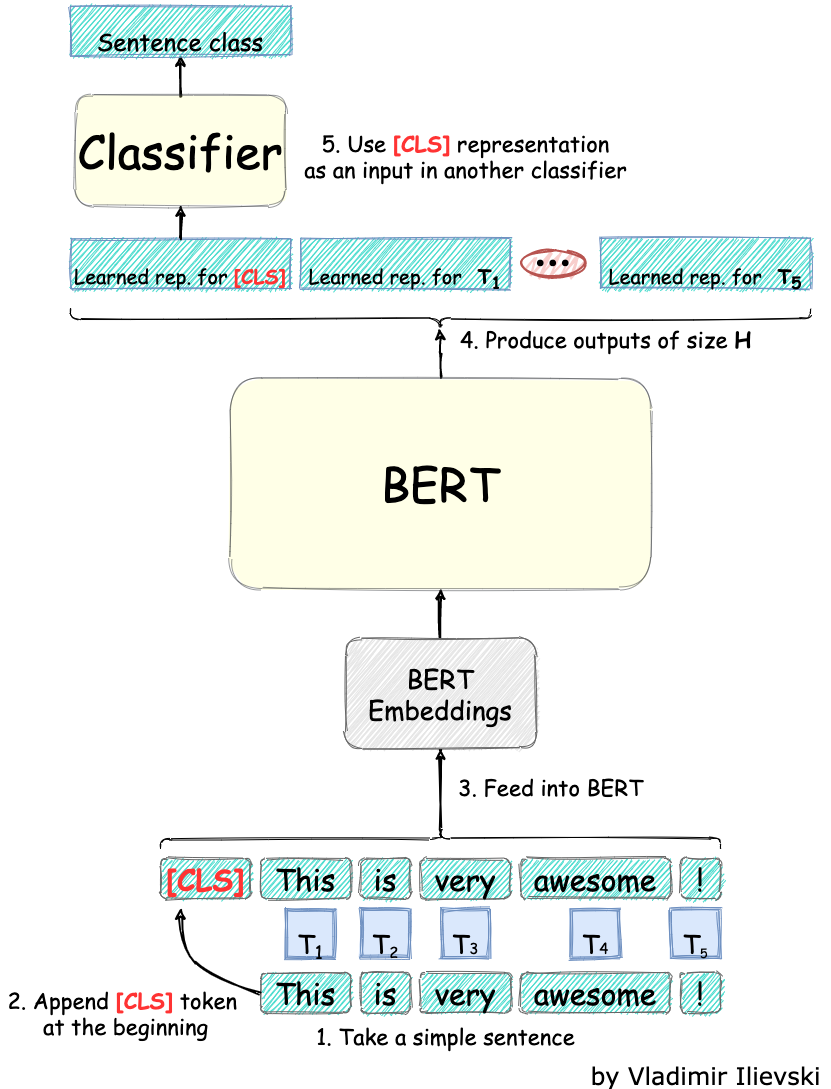
Fig. 5: BERT for text classification
We just need to take a sentence and append in front of it the special [CLS] token. After feeding the sentence into the BERT model, we use only the first output corresponding to the [CLS] token and discard the rest of the output.
One excellent resource
The paper How to Fine-Tune BERT for Text Classification along with the underlying GitHub repository represents an excellent solution to re-use and start with text classification.
BERT for Named-Entity Recognition (NER)
“Floyd revolutionized rock with the Wall” - in this sentence we all know that the word “rock” refers to the rock genre of music instead of the geological object, otherwise the sentence would not make any sense.
This is exactly the task of the Named-Entity Recognition (NER) task, to link a word or group of words to a unique entity, or a class depending on the context. Once knowing all entities, we can link them to a knowledge base or a database where we can find more info about them. In other words, it is extracting data about the data.
Use Cases
The scope of the NER is big, but these are the main relevant fields where it is applied:
- Information retrieval: by discovering the entities of the words we can understand the semantic search queries much better. This can help us to find more relevant search results.
- Building better chatbots: understand the users better. In fact, chatbots rely on NER, based on the extracted entities they can search knowledge bases, databases, and return relevant answers driving the conversation in the right direction.
- Knowledge extraction: make the unstructured data relevant. As most of the information exists in textual format, extracting value from it becomes an essential task.
How to do it with BERT
There are many different techniques for tackling the NER task including highly specialized neural network architectures. With the invention of BERT and BERT-like systems, crafting NER systems is quite handy, as illustrated below:
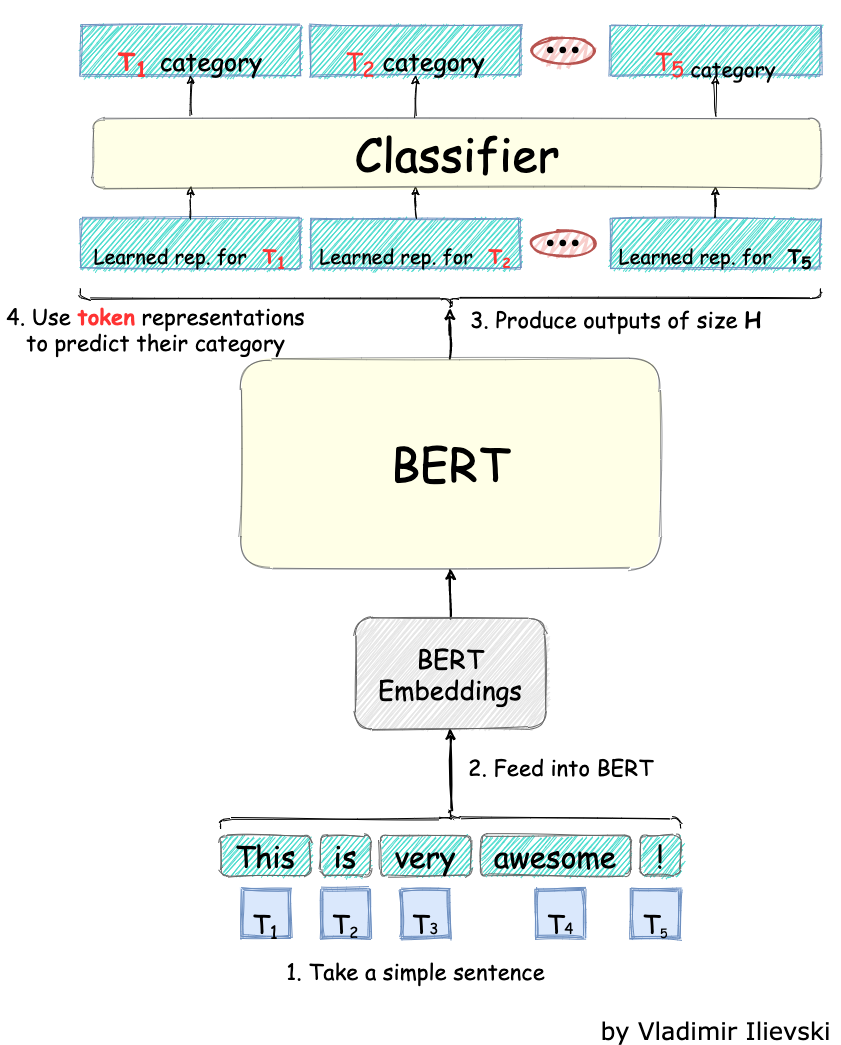
Fig. 6: BERT for Named-Entity Recognition
The tokenized sentence at the input is fed into the pre-trained BERT model. To determine the entities to which the words belong, we use the BERT learned representation for the words and feed them in a classifier.
One excellent resource
NER is one of the benchmarking tasks in the original paper, thus it is possible to use the original repository. On top of this, there are a plethora of repositories solving NER with BERT in a similar way, out of which the most comprehensive is this GitHub repository, giving a way to put it in production immediately.
BERT for Extractive Text Summarization
Imagine having a long text without an abstract, or a news article without a headline. What would you first do in this case is skim through the text in order to understand what is it about. This mundane task can easily be bypassed, if there were some automatic summary extraction system.
The task of the extractive text summarization is to automatically sample the most salient and informative sentences from a given text. This is quite convenient in many different scenarios as described further down.
Use Cases
Automatic text summarization can be applied for everything related to long documents:
- News summarization: summarizing the brimming amount of every day news articles.
- Legal contract analysis: summarizing the excruciatingly confusing and long legal documents in order to understand them in simple words.
- Marketing and SEO: crawl and summarize the content of the competitors to understand it better.
- Financial reports analysis: extract meaningful information from the financial news and reports for the sake of making better decisions.
How to do it with BERT
Performing extractive text summarization with BERT might be tricky since it is not one of the tasks for which BERT was designed to be a pre-trained model. Despite this, the BERT model is flexible enough to be customized to work in this scenario. We show how to do this in the illustration below:
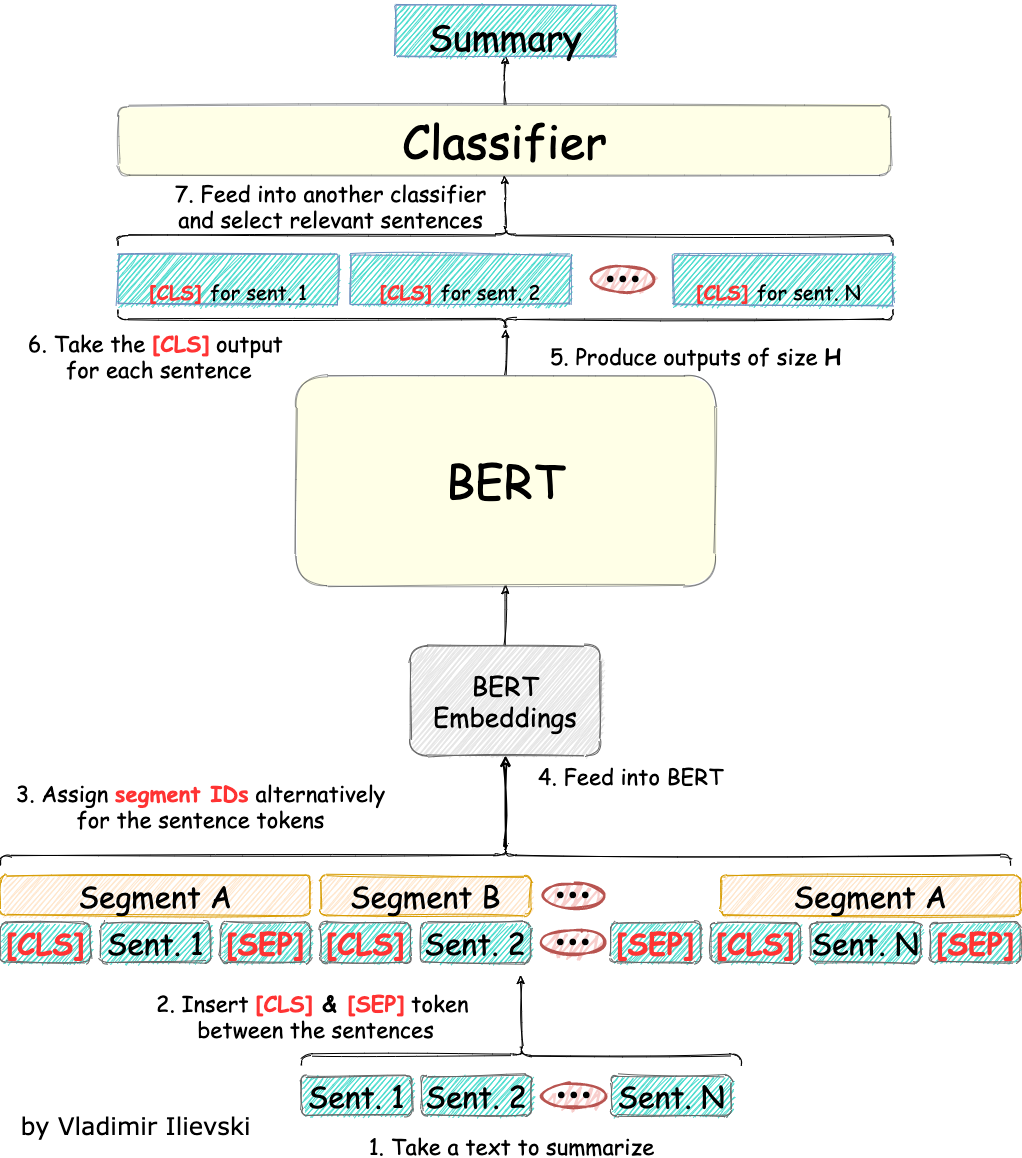
Fig. 7: BERT for Extractive Text Summarization
In this case, we operate on a sentence level, but the sentences are anyway considered as a list of tokens. To select what sentences are important, we enclose each sentence with [CLS] token on the left and [SEP] token on the right. To make the neighboring sentences depend on each other we explicitly provide segmentation tokens. For each sentence, we alternatively switch between segment A and segment B.
After feeding this composite input into the pre-trained BERT model, we only use the output representation for each of the [CLS] tokens to select the best sentences that summarize the text.
One excellent resource
The work in the paper entitled Text Summarization with Pre-Trained Encoders along with its associated GitHub repository presents the system called BertSum. This system can serve as a very good foundation in developing more specialized text summarizers based on BERT.
If this is something you like and would like to receive similar posts, please subscribe to the mailing list below. For more information, please follow me on Twitter or LinkedIn.
Conclusion
The purpose of this text is to elicit the machine learning practitioners as well as the decision makes in the business domain to start adopting the new paradigm shift.
With illustrated examples, we see how we can easily use and adapt a pre-trained BERT model on a variety of tasks including: text classification, named-entity recognition and extractive text summarization.
In future, this zoo of high performant pre-trained models like BERT will become more important and relevant. We see this from the recent developments, for instance the creation of the GPT-3 model. This might be the push we all need in achieving our goals. Thus, let’s grab this chance and use the momentum.
Leave a comment